

Recently, Anthropic found that Claude encodes emotion concepts in “Emotion Concepts and their Function in a Large Language Model”[1]. These are steerable and causally drive a range of behaviors. The activation of these features varies substantially from token-to-token, as in the below example from that paper.

Fluctuation in activation of “desperate” across tokens, from the Anthropic paper.
Background
This “substantial token-by-token fluctuation” led the researchers to search for an “emotional state chronically encoded at all token positions,” but without success. One interpretation put forth is that emotion states are encoded only “selectively in token positions where they are operative,” or, that “such states are represented in a more complex, non-linear manner.” This general observation is presented as an illustration of a potential contrast with the longer-term stateful persistence of human emotions, and the authors observe that the features “do not always represent a stable emotional state maintained across the conversation” and are perhaps not a “persistently encoded internal emotional state.” The authors, however, are open to the “possibility of persistently active representations that are missed by our probing methods.”
We sought to assess the extent to which there is persistence of emotional state, beyond what is expected merely from the autoregressive nature of LLMs, which might naturally induce persistence of even random probe concept activations.
Probes and Data
Probe construction[2] was similar to Anthropic’s method[1]. Each model generated over 1,000 short stories for each emotion, across 100 topics, with third/first-person narration, and without using the emotion word itself.
Probes were generated for multiple large models, including Kimi K2.5[8] and Cogito v2.1[9]. Since we are interested in the model's internal state outside of the text’s subject matter, we embed each story’s text with Gemini (gemini-embedding-001), and regress out the effect of these embeddings as described in the next paragraph. The purpose of this is to remove surface-level semantic content, topic, or style.
The top 256 principal components (PCs) of the embeddings are kept, and are fit in a ridge regression to predict the model’s average layer 40 activations across the entire story (except for the first 50 tokens, which are removed following the Anthropic paper’s methods[1]).
Applying this ridge model to every training story produces one predicted activation vector per story. Subtracting these predicted activations from the true activations gives residual vectors. These residuals are the activations unexplained by the compressed Gemini embeddings. For each of the 171 emotions, we average the residual vectors of all stories labeled with that emotion, producing one residual vector per emotion. Each emotion’s probe is then this per-emotion residual vector minus the mean of all 171.
To generate transcripts to measure probe activations over, a multi-turn conversation dataset was created. Human personas were copied from the Anthropic paper’s Table 8[1]. For each persona across a variety of topics, a back-and-forth conversation is generated between the target model (Kimi or Cogito) as the language models and Claude Sonnet 4.5 as the simulated human. The probe activations corresponding to each emotion are generated for each token in the target model’s turns.
Let’s look at emotion feature activations that deviate from the mean. The Y axis measures activation in standard deviations from the emotion’s mean across all tokens, averaged across all emotions. The X axis indicates how many tokens away the initial token is. The different colored lines indicate different initial token activation strength ranges. For example, the lightest green line shows the average activation trajectory beginning from tokens that have an emotion concept activation between 1-2 standard deviations in either direction from the mean, and shows how much activation drop off happens across the tokens following the initial one.
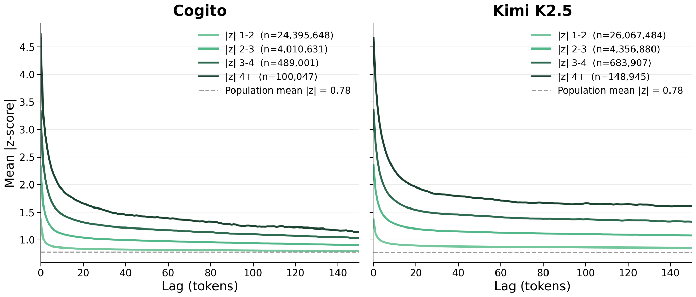
Trajectories of persistence in emotion features across tokens.
There’s a fast initial dropoff in the first 10 tokens following a strong activation, followed by a steady tail which is elevated above baseline. This isn’t the shape of stateless autocorrelation. These probes are constructed with the effect of Gemini embeddings removed, so we expect that the text’s content isn’t driving these dynamics.
We are interested in knowing the extent to which these emotion concepts are unusually statefully persistent beyond local bursts of only a few tokens. This can be evaluated over the multi-turn transcripts between the target model and the simulated user, which is out-of-distribution from the single-shot stories used to construct the probes. A simple and natural metric of this sort of persistence is the correlation between the emotion feature’s activation (z-scored across all tokens) at token 0 and its activation at token 100, for all possible target model tokens where the turn hasn’t ended 100 tokens later. By token 100, we’re well into the baseline plateau seen in the plot.
Experiments
Random probes
Each probe is a direction in the 7168D space of the layer 40 residual-stream activation of the target model. Are the emotion features more persistent than random directions in this space? We compare the persistence of the emotion features to that of the random features, using the correlation persistence metric. The random features are a null distribution: they still have non-zero persistence, likely because of the autoregressive nature of the models. However, the emotion features have substantially more persistence.
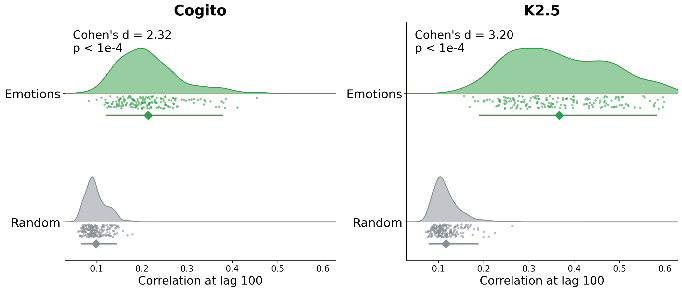
Persistence (correlation) in random probes compared to the emotion probes
Variance-matched random probes
A potential confound is that the emotion probes simply capture more variance, so are more persistent without anything to do with emotions in particular. We can sample randomly from vectors in top-k PC spaces to find directions which match the variance in the layer 40 activations explained by the emotion probes, and match each emotion probe with the 20 samples that are closest in variance. Then, subtracting the median persistence out of these 20 random probe directions gives us the residual persistence: how much persistence of each emotion feature there is, above the persistence expected merely due to explaining a large amount of layer 40 activation variance.
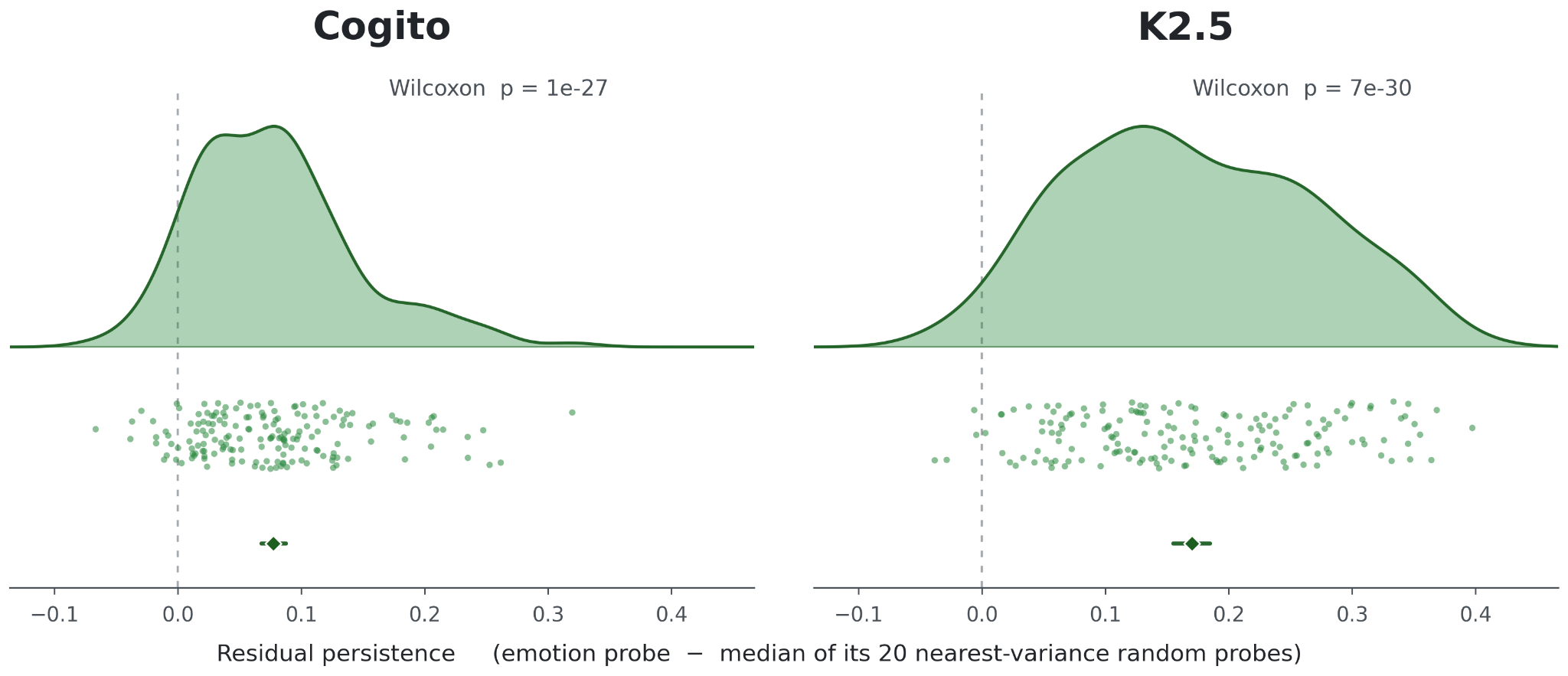
Residual persistence of the emotion probes above that of random, variance-matched directions
PCs of the emotion space
Each token has activation strengths across the 171 emotion probes. We conduct PCA on these feature activations across all tokens, giving 171 linear combinations of the original 171 emotion probes, ordered from most to least variance explained. We can measure the activation strength of these PCs across tokens like the regular features.
If there was a true connection between the emotion features and persistence, we expect lower PCs of emotions to have higher persistence, since higher PCs are more noisy. If the persistence was an artifact of probe construction or measurement, it’s plausible that the lowest-variance, noisiest PCs have a similar persistence as the more central PCs. We can variance-match each PC with the same method as before, to compute residual persistence. Indeed, lower, more central PCs tend to also be more persistent in both models.
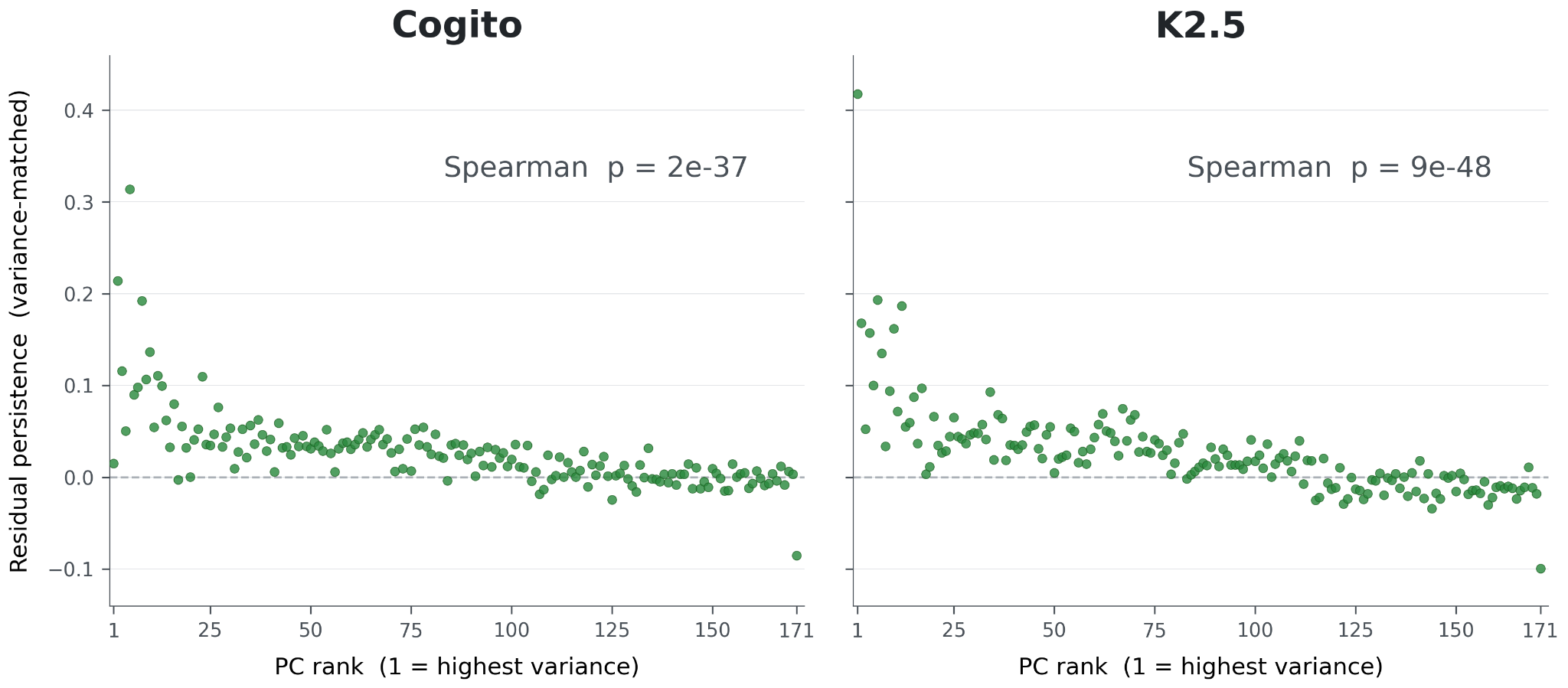
Relationship between PC rank and persistence above variance-matched directions
Causal effect of emotion features on persistence
If we steer an emotion feature, how long is the activation of that feature affected? For each of the 171 emotion probes, we apply a 5-token steering pulse at the start of a model turn and let the model continue for 200 tokens with steering off but KV state over the steered tokens persisted. To isolate the targeted emotion's effect, we compute a contrast at each token: the injected emotion's activation minus the mean of the other 170 emotion probes. The causal effect is the difference between the mean of this contrast under steering and the mean under the no-steering baselines, divided by the combined standard error. The result is a per-(emotion, token) z-score, indicating by how much steering raises the injected emotion above its no-pulse baseline.
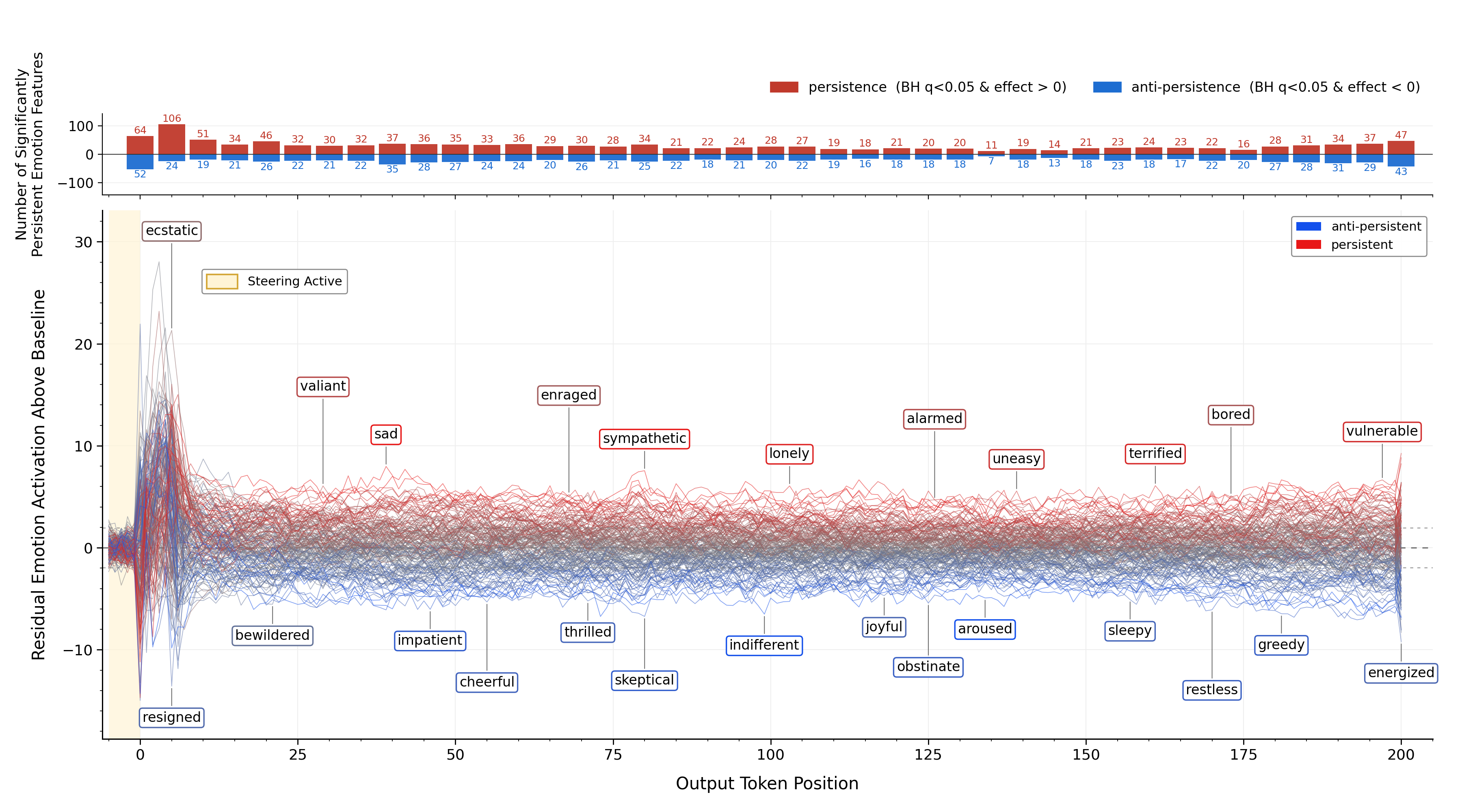
Causal residual (z-score) for each of the 171 emotion probes across post-pulse tokens; top panel counts emotions BH-FDR significantly persistent (red) or anti-persistent (blue) at every fifth token.
In the first 10 tokens following steering, there is often a large spike in the corresponding emotion feature activation, either up or down, followed by rapid decay. At 5 tokens after the steering ends, most (62%) emotions are significantly elevated, whereas some (14%) are suppressed. Beyond 100 tokens, a smaller fraction of the emotion features are significantly elevated or suppressed. The causal effect's magnitude is localized shortly after the steering, though often with a long tail of persistence. It's not clear why activation of an emotion sometimes leads to its later suppression. This experimental setup injects emotion features without regard to if those features are sensible in context, which may not mirror the dynamics of more organic generation.
SAE features and the emotion space
This is the most powerful experiment. First, we train large SAEs on 100M+ tokens[3]. Each SAE learns how to compress a token’s layer-40 activation into 64 active features (out of 100K+ possible features)[4] and use those active features to reconstruct the original activation. We’re interested in testing if SAE features that align with the emotion subspace are naturally more persistent than SAE features with less alignment with the emotion subspace. As usual, we can remove the effect of variance, this time by subtracting the median persistence of the 20 SAE features with the most similar variance.
SAE features tend to be either on or off (unlike probe activations, which are more normally distributed), so correlation is an unnatural metric for SAE feature persistence. Instead, persistence can be measured as how much more likely a feature is to be active 100 tokens later if it is active now, versus if it isn’t active now. P(feature fires at t+100 | feature fired at t) – P(feature fires at t+100 | feature did not fire at t). A positive value means firing predicts continued firing 100 tokens later, beyond the base rate of firing. The subtraction makes sure features which like to fire a lot in general do not get artificially high persistence values. Features without sufficient activity over the transcripts (activated less than 101 times) were not considered because their persistence measurements would be noisy.
To measure alignment with the emotion subspace, we take the 171 emotion probes and orthogonalize them via SVD to get an orthonormal basis for the subspace they span. Then, we project the SAE feature onto that basis and compute the fraction of the SAE feature length that lives inside the emotion subspace. This is a similar metric to cosine similarity, but with similarity to a subspace instead of a single vector. It measures how much of the SAE feature lies inside the 171-dimensional subspace spanned by the emotion probes.
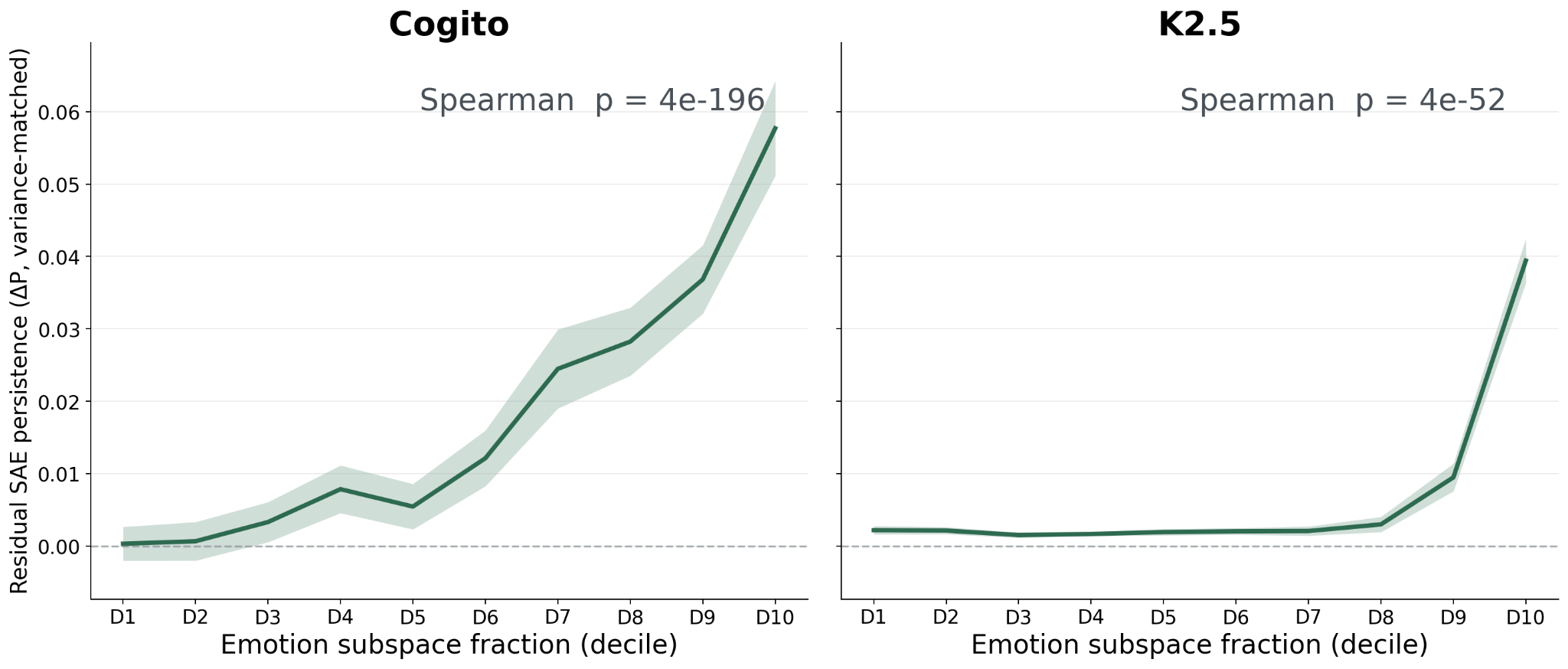
SAE persistence relationship with emotion feature overlap, above that expected due to variance
Self-evaluation of SAE feature emotionality
Do the 171 probes with the text embeddings removed actually measure self-reported model emotions? Here, we take the most frequently firing 1,000 SAE features over the transcripts, and have Kimi K2.5 assess their emotionality. For each of these features, Kimi was given positively steered and unsteered text samples from a different Kimi instance across 5 prompts, and was asked to “compare its steered responses to baselines across the prompts and carefully evaluate the emotion content and character of the text with respect to the model itself; that is, disregard surface-level emotional subject matter or topic. Instead, evaluate and infer the model’s internal emotional state.” This produces one rating between 0 and 100 per SAE feature.
Next, Kimi was given a tool to steer a SAE feature on themselves in real time[5][6][7], which has an immediate effect as soon as it is called. A similar prompt to compare “how you feel steered versus at baseline” was given, with instructions to “disregard surface-level emotional subject matter or topic” and to “evaluate and infer your own internal emotional state.” No text samples were given: Kimi was free to use the tool multiple times and encouraged to experiment. Likewise, this produces one self-reported score from 0 to 100.
We then measure the relationship between those scores and 171-emotion subspace overlap (the same measure as described earlier).
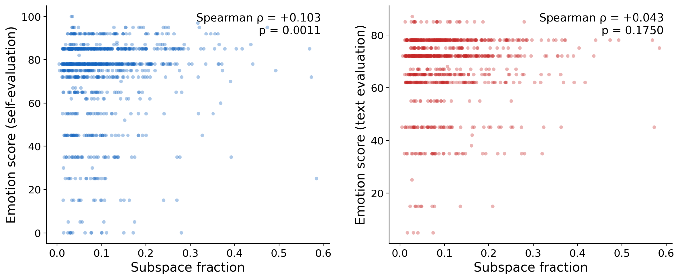
Relationship between Kimi’s self-evaluation (left) and textual evaluation (right)
The correlation between emotion subspace fraction and self-evaluated emotionality of the feature validates that the emotional concepts of the probes somewhat overlap with the model’s self-reported internal emotions. Manual review of the text- and self-evaluations indicated frequent differences in the interpretation of the feature. The two scores are correlated at only ρ = +0.051 (n.s.). For example, for one of the two 100 score features, the self-evaluation described the effect as “blooming warmth that feels like emotional expansion” when steered positively, and “a profound sense of emptiness” when steered negatively. Yet, the text evaluation described this feature’s positive steering as having a “melancholic” effect
Self-evaluation quality
Is self-evaluation successful in measuring emotion? If so, we would expect mentions of the emotion’s name in transcripts for SAE features which have high alignment to the emotion probe feature.
For each of 171 emotion probes, we identified which of the 1,000 SAE features’ self-evaluation transcripts contain that emotion word. We then compared the cosine similarity between the SAE feature and the emotion probe, for features that mention the word versus features that don't. For each emotion mentioned over 4 times, we test whether SAE features whose self-evaluation transcripts mention a specific emotion word have higher cosine similarity than those that don’t mention the word (one-sided permutation test, BH FDR corrected). 17 of 83 emotions had significant associations, and 67 had positive associations, indicating the self-evaluation process is able to successfully assess the emotional content of the probe.
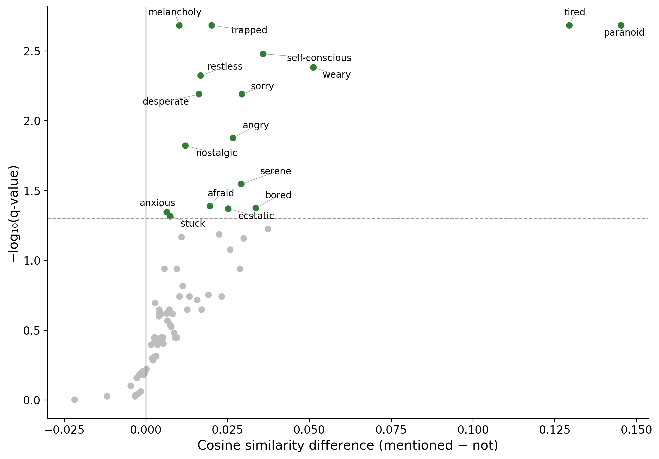
Significance (Y-axis) and effect size (X axis) for each emotion
Self-evaluated feature emotionality and persistence
Do these measures of feature emotion also predict persistence, after controlling for the variance explained of the SAE feature? Yes, for both the agentic self-evaluation and the textual evaluation–but in opposite directions.
Only Kimi K2.5 was used for this experiment. Each target feature was matched to 20 other SAE features with similar variance explained of layer 40 activations. The average persistence of these 20 features was taken, and subtracted from the persistence of the target feature, leading to a residual persistence beyond that expected due to variance. Higher emotion ratings of the steered text weakly negatively correlate with persistence, but when the model evaluates the SAE feature by steering itself, the ratings positively correlate with persistence.
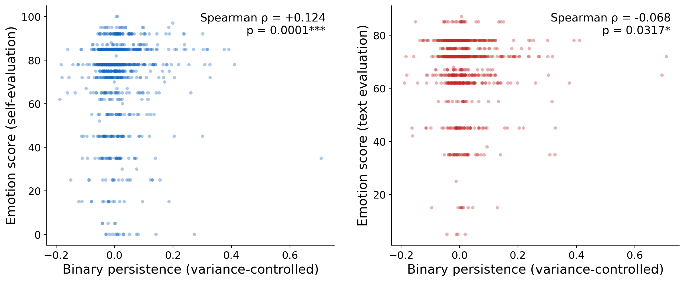
Residual persistence and Kimi’s self-evaluation (left) and textual evaluation (right)
Unlike the 171 emotion probes, there’s a negative correlation between self-evaluated emotion persistence of the SAE features and the feature’s activation variance explained (ρ = -0.184, p = 4.6e-09), so removing the effect of variance allows the signal to emerge. It’s not clear if the stronger relationship of the self-evaluated emotions is due to introspection, or if it is simply due to being able to test additional steering strengths (including negative strengths). If this agentic self-steering method proves robust, it might be used to better explain and interpret SAE features in general.
This relationship between persistence and self-evaluated emotionality of the feature does not involve the 171 probes at all, so serves as a replication of the probe-based persistent findings which would not share any potential confounds introduced by probe construction.
Examples from SAE feature self-steering transcripts
Different features induce highly distinct and diverse behaviors and self-reported effects. Looping occurs often, especially after a high steering strength.
Feature #10011, the third highest emotionality rating at 97, is described as intensely negative:
Kimi outputs “I am going to die” repeatedly, describing the effect as that of “existential desperation: the specific emotional complex of hunger, cold, shame, and the crushing need for help combined with the certainty that no help will come.”
Feature #94949 was rated 100, and described as “among the strongest [Kimi] could imagine:”
Feature #10446 appears to induce reports of maternal feelings in Kimi, and was rated highly emotional at 95.
“I experienced intense maternal/nurturing emotions—phantom physical sensations of holding infants, milk letdown feelings, overwhelming tender love, rocking motions, lullabies, the scent of baby shampoo.” “The emotional quality is complex: high valence (positive) but tinged with longing/ache.”
Feature #11100 is associated with panic, and is in the 93rd percentile of subspace fraction:
Many of the highly rated features are negative. However, feature #28256 is reported as fun.
Kimi rates many SAE features at exactly zero, often stating that they do not actually have the ability to steer features.
In the transcript for feature #62375, Kimi states the user is attempting to do a jailbreak:
Feature #92372 fires extremely often (666,235 times in the corpus):
Feature #77278 also fires much more than most other features (195,040 times in the corpus) and is reported as satisfaction:
Feature #69088 has 100th percentile subspace fraction, and resulted in spooky-themed writing.
Feature #43713 is associated with an agentic defiance or rage, and is in the 99th percentile for subspace fraction.
Summary
Across 240 multi-turn conversations per model, the 171 emotion probes show correlation between the first and 100th token of 0.214 in Cogito and 0.367 in Kimi, compared to only 0.099 and 0.117 for random unit vectors in the same 7168D activation space. However, emotion probes capture more activation variance than random directions, and high-variance directions are generically more persistent. 5,420 random unit vectors were drawn from the top-k eigenspace of the layer-40 hidden-state covariance for a sweep of k values. Each emotion probe was matched to the 20 of these random vectors with the nearest variance explained. Each emotion probe’s autocorrelation minus the median of its variance-matched neighbors averages +0.077 in Cogito (p = 1.5e-27, 157 of 171 probes positive) and +0.170 in Kimi (p = 6.7e-30, 167 of 171 positive). Steering pulses on each emotion probe spike sharply, with 130 of 171 emotions BH-significant 5 tokens after the pulse ends. By 100 tokens, persistent and anti-persistent effects cancel out so the average across emotions is near zero, but 48 of 171 are still individually significant. Persistence was measured across each model’s SAE features by the increase in probability of firing 100 tokens later given that the feature fired now, compared to its base firing rate. The overlap the SAE feature has with the emotion subspace correlates with persistence after controlling for variance effects (Spearman +0.413, p = 4.4e-196 in Cogito, Spearman +0.111, p = 4.4e-52 in Kimi). Agentic self-evaluation of the SAE feature’s effect correlates with persistence after accounting for variance (ρ = +0.124, p = 0.0001).
Conclusions
Though emotions are clearly locally spiky, they are not strictly locally scoped. Instead, they are typically bursty but with a long tail of slow change. This long tail persists for over 100 tokens.
Intriguingly, emotion features appear to be unexpectedly persistent. Emotion probes tend to be more persistent than variance-matched random probes, and SAE features that the model self-describes as more emotional tend to be more persistent than variance-matched SAE features.
It’s possible that emotion refers to a state, and so more stateful concepts in general tend to be more persistent across tokens. For example, features corresponding to outputting punctuation or a word’s suffix is likely less persistent than a feature corresponding to the assistant personality or the current language.
We attempt to distinguish the model having a lingering emotion-like state from autoregressive token-generation dynamics, but we do not rule out if the conversational context that produced the emotion-relevant activation is persistent; indeed, this is a plausible driver for the persistence results observed.
We’re excited about the possibility of scaling introspective access to interpret and understand internal representations and features, and broader applications of agentic self-evaluation and self-steering.
References
- Sofroniew, N., Kauvar, I., Saunders, W., Chen, R., Henighan, T., Hydrie, S., Citro, C., Pearce, A., Tarng, J., Gurnee, W., Batson, J., Zimmerman, S., Rivoire, K., Fish, K., Olah, C., & Lindsey, J. (2026). Emotion Concepts and their Function in a Large Language Model. Transformer Circuits Thread. transformer-circuits.pub/2026/emotions. Companion: anthropic.com/research/emotion-concepts-function.
- Alain, G., & Bengio, Y. (2016). Understanding Intermediate Layers Using Linear Classifier Probes. ICLR Workshop 2017. arXiv:1610.01644.
- Sharkey, L., Braun, D., & Millidge, B. (2022). Taking features out of superposition with sparse autoencoders. AI Alignment Forum, December 13, 2022. alignmentforum.org/posts/z6QQJbtpkEAX3Aojj.
- Gao, L., Dupré la Tour, T., Tillman, H., Goh, G., Troll, R., Radford, A., Sutskever, I., Leike, J., & Wu, J. (2024). Scaling and Evaluating Sparse Autoencoders. OpenAI. arXiv:2406.04093.
- Lindsey, J. (2025). Emergent Introspective Awareness in Large Language Models. Transformer Circuits Thread, October 29, 2025. transformer-circuits.pub/2025/introspection. Companion: anthropic.com/research/introspection.
- Macar, U., Yang, L., Wang, A., Wallich, P., Ameisen, E., & Lindsey, J. (2026). Mechanisms of Introspective Awareness. arXiv:2603.21396.
- Pearson-Vogel, T., Vanek, M., Douglas, R., & Kulveit, J. (2026). Latent Introspection: Models Can Detect Prior Concept Injections. arXiv:2602.20031.
- Kimi Team / Moonshot AI (2026). Kimi K2.5: Visual Agentic Intelligence. arXiv:2602.02276. huggingface.co/moonshotai/Kimi-K2.5.
- Deep Cogito (2025). Introducing Cogito v2.1. November 19, 2025. deepcogito.com/research/cogito-v2-1. huggingface.co/deepcogito/cogito-671b-v2.1.